
We’re in the final stretch before Dreamforce, and we’ve added new and exciting features to the DataGroomr platform including extended AI capabilities, additional flexibility in the matching models, more control to Brushr transformations and filtering in dataset views. Let’s dive right in by looking at our most exciting AI feature yet!
DataGroomr AI Assistant
We’re excited to introduce the latest addition to DataGroomr: a Generative AI Assistant. This new feature leverages advanced AI to contextually identify key differences between records, enabling you to make faster, more accurate decisions based on both visible similarities and subtle, previously unseen discrepancies. As with everything we build, trust is at the core of this feature. Our generative AI functionality is privately hosted, ensuring that your data is never stored within the AI model and never leaves the secure environment of the DataGroomr platform.
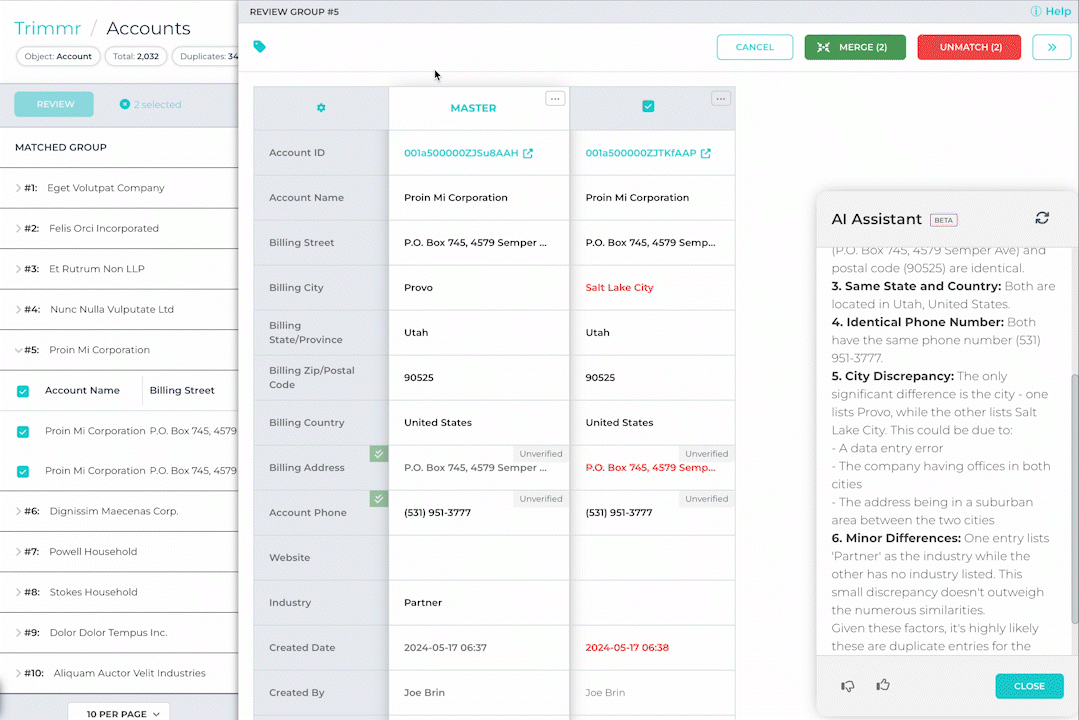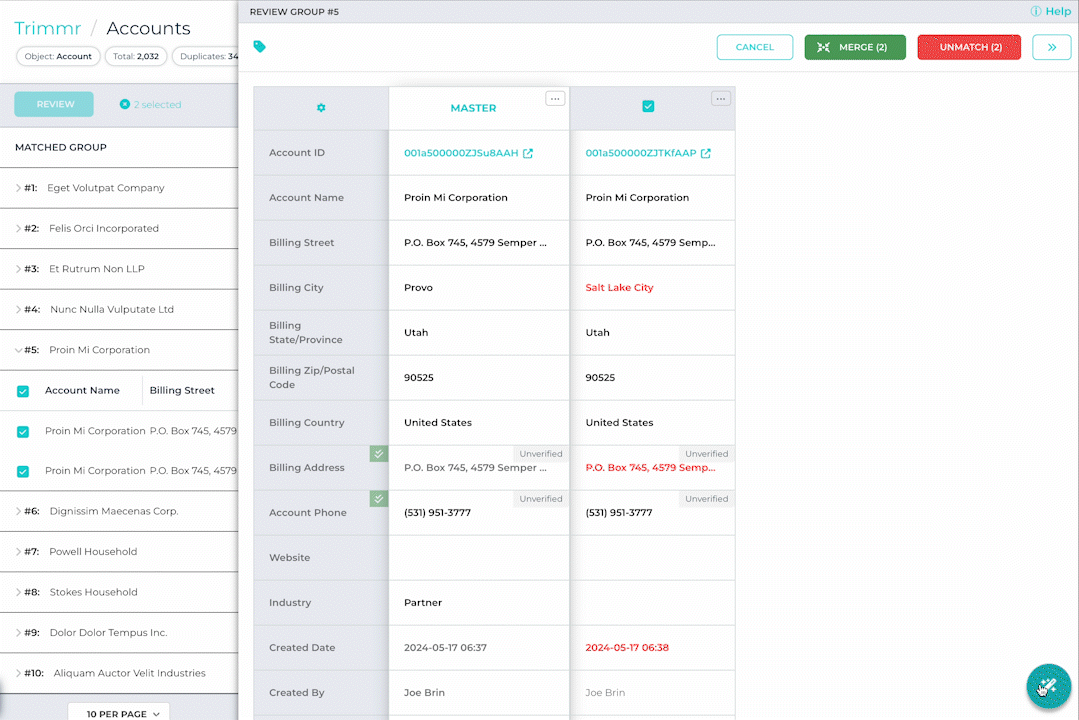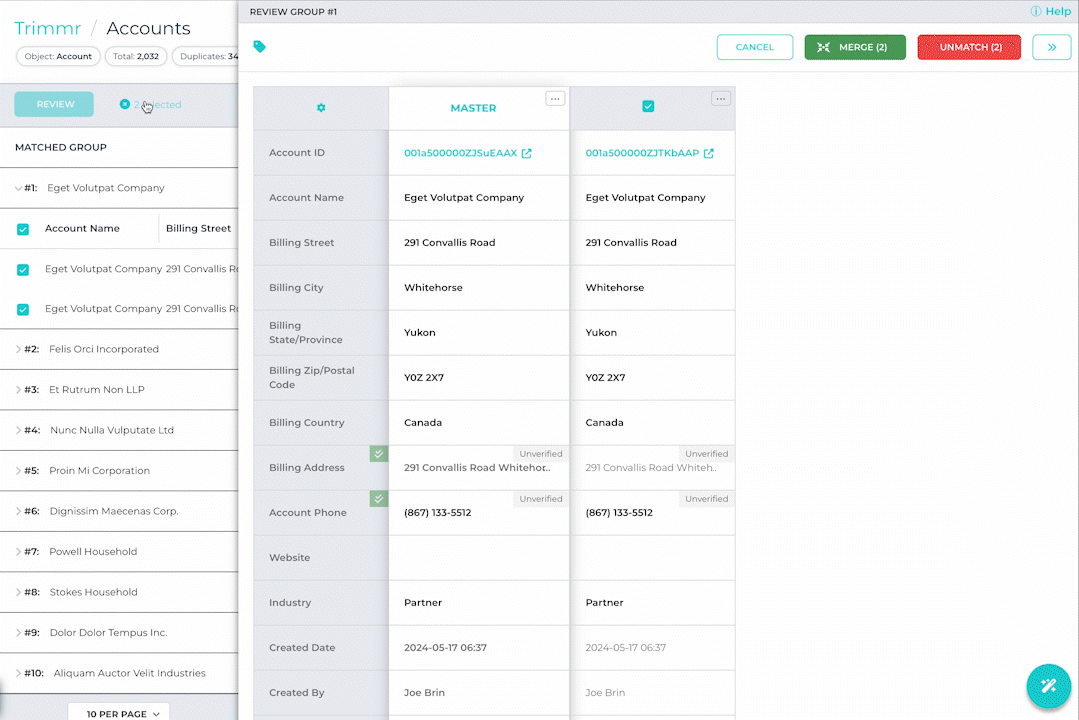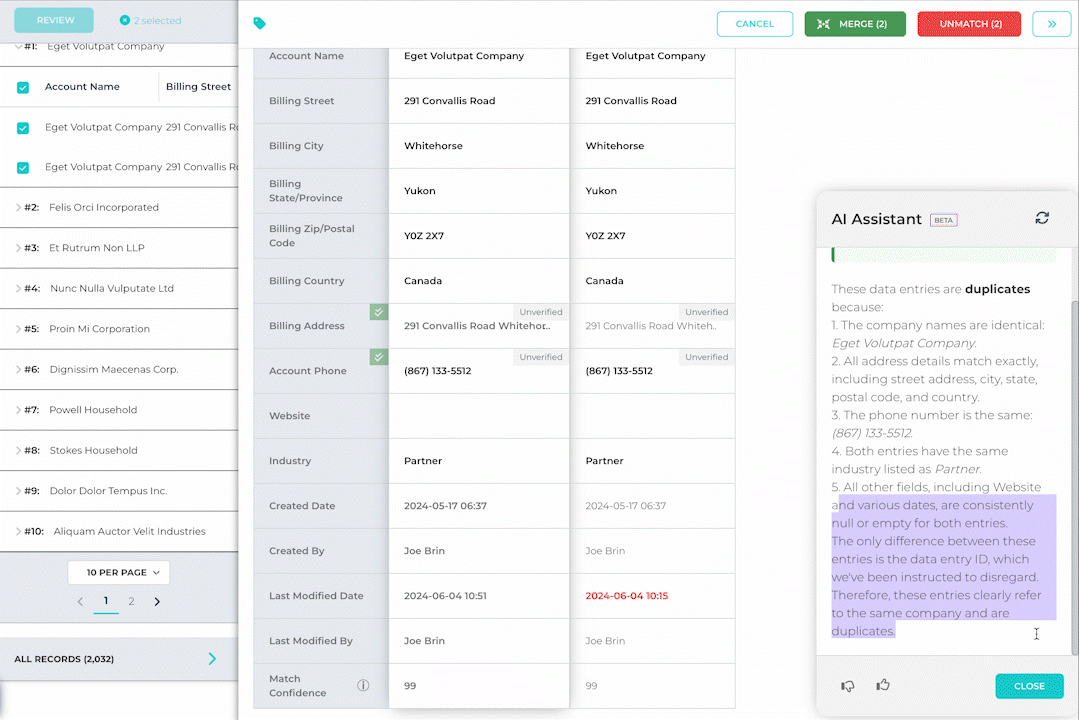
Still unsure of whether you’re ready to adopt AI? Worry not, the AI Assistant feature can be easily disabled in DataGroomr settings.
Matching Models Improvements
Several additions were released to make matching models more flexible for both the Machine Learning type and classical matching models.
Cross Compare Fields
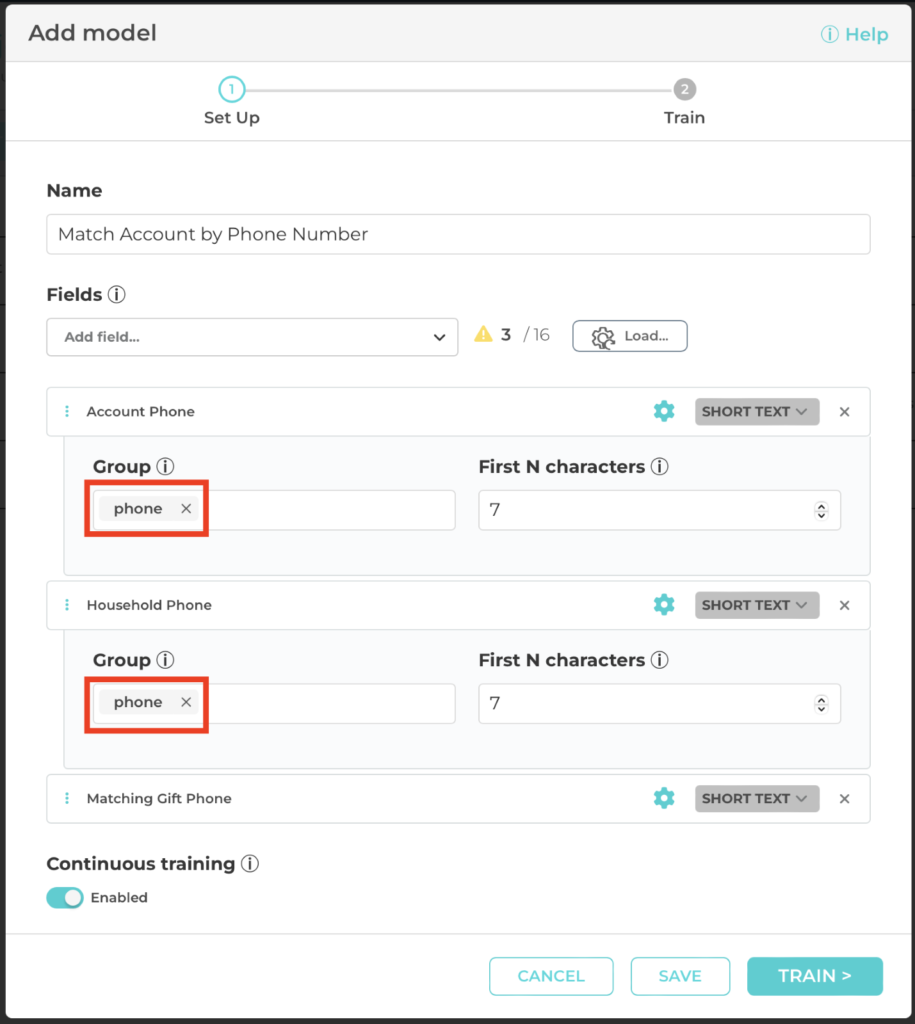
With DataGroomr, you can now create customized Matching Models that identify duplicate records by matching values across different fields. Take for instance two duplicate records that have the same phone number stored in different fields, for example in Mobile and Home phone fields. While the previous matching model identified records with matching Mobile-to-Mobile and Home-to-Home Phones, the new models now add Mobile-to-Home Phone matching. This new feature gives users the ability to treat all phone numbers as a group; allowing you to cross compare and detect duplicates in mis-entered fields.
First N Characters
Also added is the ability to compare the first N characters in field values. This feature is useful for scenarios like loose comparisons of names, or phone number comparisons where only the values preceding an extension number should be evaluated.
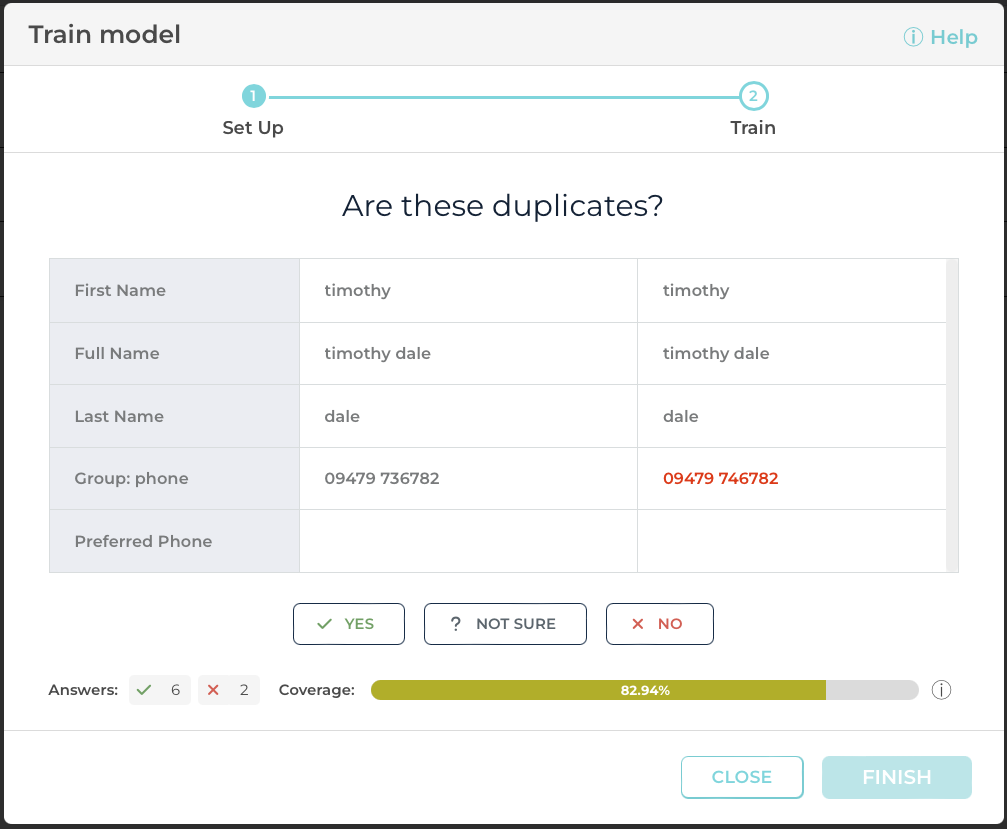
Model Coverage During Training
Ever wonder what is inside of the AI black box? Wonder no more! We’ve added more clarity and transparency to our machine learning training process by showing you the predicted coverage as you train the model. Coverage is an indicator that shows if model has effectively learned to classify pairs of records as duplicates or not, it helps in determining if a model needs more examples or it’s already confident in predicting duplicate matches. As you answer questions on whether records are duplicates, the coverage changes; the higher the score, the more confident a model is that it has learned enough patterns about your data to be able to make future predictions.
Simplified DataGroomr Lightning Component Tagging
DataGroomr’s Lightning Component has been widely installed and utilized by our customers. It gives the ability for any Salesforce user (with access) to determine if the records they are working on have been identified as potential duplicates.
Designated Salesforce users also have the ability to Tag the group (or even merge). These tags are then used by DataGroomr administrators to review and mass merge records. In this release, we have streamlined and further simplified the tagging and permissioning within the component.
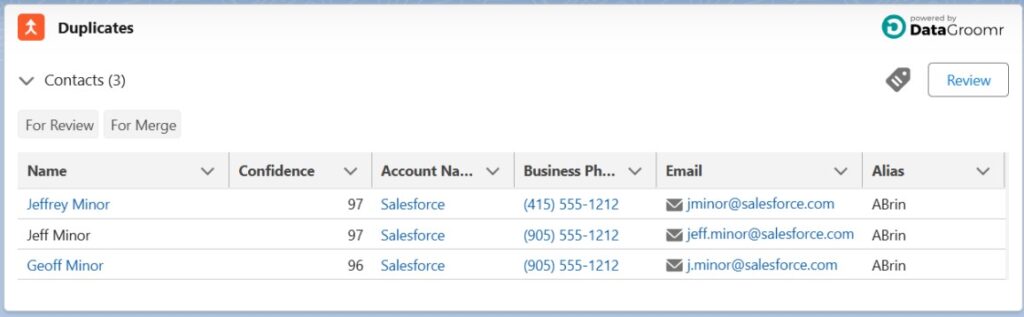
LWC tagging by Salesforce users is now included with your DataGroomr subscription at no extra charge
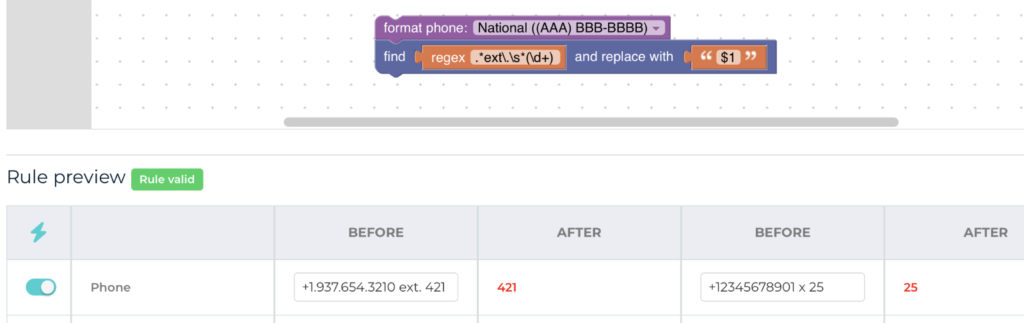
Regexes in Transform Rules
A popular request, searching with regular expressions (regexes) has been incorporated into the DataGroomr platform. Regexes can be entered in transform rules to create rules that extract extension values out of phone numbers, standardize serial numbers or create transformations that weren’t previously possible.
First, create a Brushr Transform rule with a “Find and replace” block. Then add a regex conditional and replacement string text. Finally, execute the transform rule on a target field.
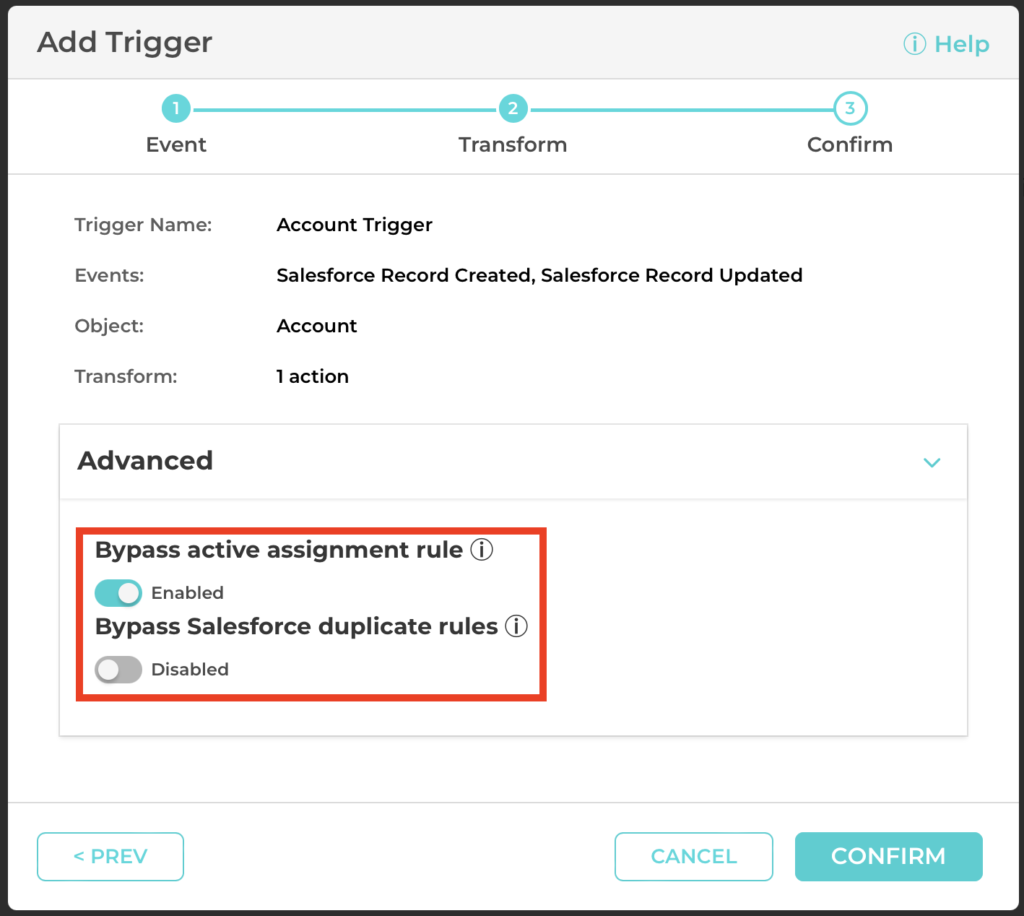
Bypass Duplicate and Assignment Rules in Triggers
In addition to Trimmer datasets, Triggers can now bypass Salesforce Duplicate Rules and Assignment Rules, streamlining business logic and processes.
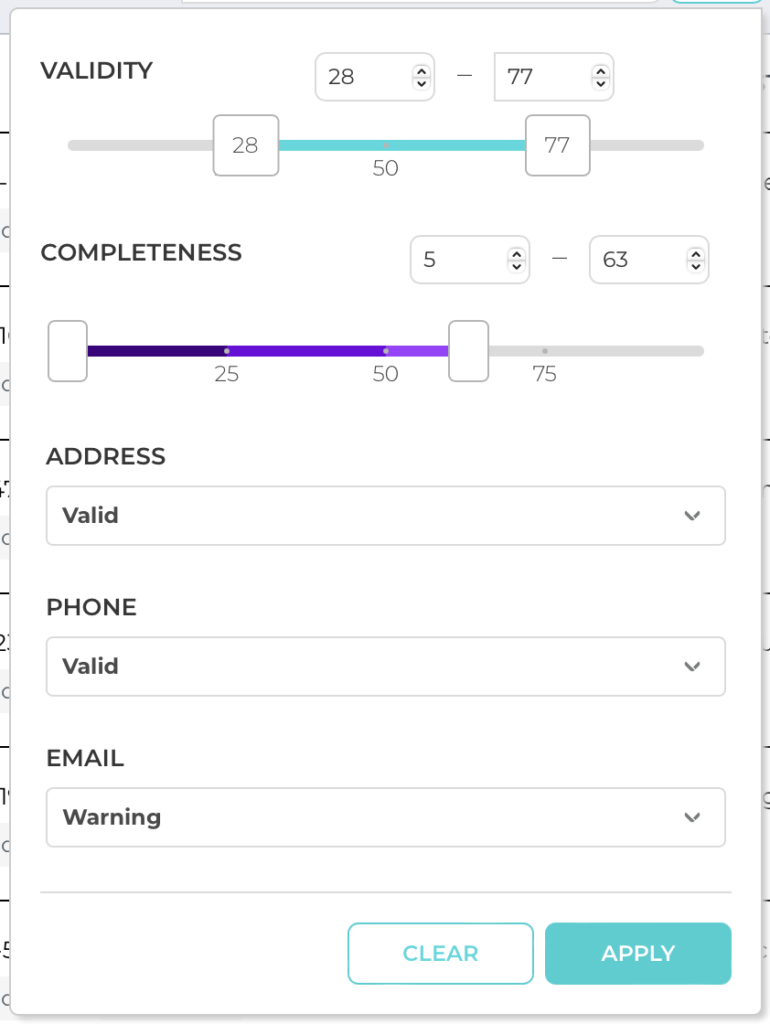
Exact Score Filtering in Brushr
Integer input boxes have been added to Brushr’s filtering and Mass Actions menu. In addition to filtering datasets by sliding low and high value thresholds, integer input boxes allow for fine grain filtering within mass actions on records inside of Brushr datasets.
Extension to DataGroomr API
Based on your feedback, we’ve extended API with two new endpoints, for verifications and records IDs.
Verification API
The ability to leverage DataGroomr’s verification capabilities is now accessible through the Verification API, allowing users to use verification on phones, emails and mailing addresses within forms, external systems and automated bulk verifications. Values verified through the API will be reflected inside of Salesforce if sync is enabled.
Learn more about the DataGroomr Records API here
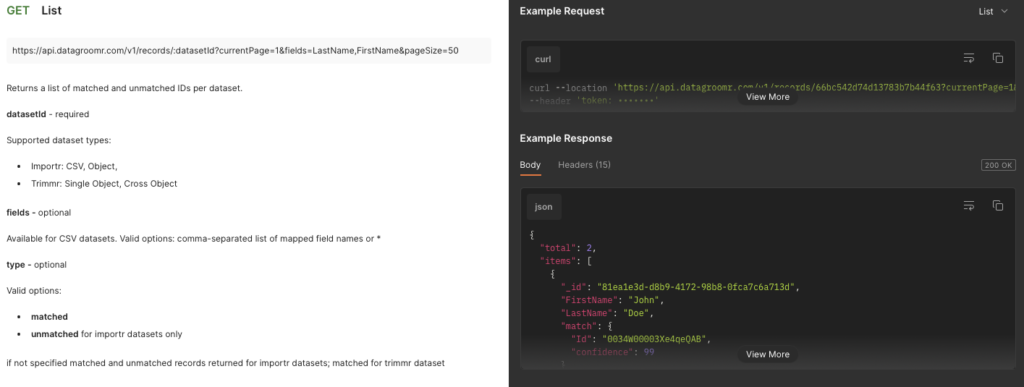
Records API
New records endpoint allows to get a list of matched and unmatched records. It’s available for Trimmr and Importr datasets, although it will be particularly useful in combination with Ingestion API, where after submission of CSV records for duplicate detection, you’ll be able to get a response of what records were matched and which records are new. Learn more in DataGroomr API documentation.
What’s Next?
That’s a wrap for this month’s release. As always, we appreciate your feedback! If you have any feature suggestions or product enhancements in mind, please submit them to our Ideas Portal. Thanks for tuning in to this edition of our release notes!
Happy DataGrooming, Trailblazers!









