

As artificial intelligence becomes woven into Salesforce, marketing automation, and enterprise knowledge systems, one factor determines whether AI succeeds or fails: data quality. While most teams understand the risks of missing or outdated data, a quieter threat lurks beneath the surface – duplicate content.
Duplicate or near-duplicate records, documents, and knowledge articles can silently erode AI accuracy, waste compute resources, and undermine user trust. In this post, we’ll explore how duplicates damage AI systems inside Salesforce and beyond – and how DataGroomr helps organizations eliminate them before they do harm.
What Is Duplicate Content?
Duplicate content refers to identical or highly similar records, documents, or data entries that appear multiple times within a dataset. In Salesforce and connected platforms, duplication can take many forms:
- Leads, contacts, or accounts entered multiple times with slightly different names
.
- Knowledge articles that contain the same information reworded for different audiences
.
- Imported data from multiple sources that overlaps or repeats existing entries
.
- Text or metadata duplicates that confuse indexing, search, or AI retrieval systems
.
At first glance, these might seem like minor inconsistencies. But for AI systems – especially those using retrieval-augmented generation (RAG) or large-language-model inference – duplicates can have far-reaching consequences.
How Duplicate Content Affects AI Systems
1. Conflicting or Redundant Responses
When an AI model encounters multiple versions of the same information, it struggles to decide which one is authoritative. The result is confusion, inconsistency, or outright contradiction in responses.
Example:
A Salesforce Service Cloud org contains two KB articles titled “Resetting a Customer Password” — one written in 2022 and one updated in 2024. If your Einstein-powered assistant retrieves both, it may present outdated instructions alongside the correct ones, leaving the user unsure which process to follow.
Impact: Users receive mixed answers, and trust in AI guidance drops. The more duplicates in your knowledge base, the higher the chance of conflicting retrievals.
2. Lower Retrieval Precision
Duplicate records inflate the dataset without adding real diversity. AI systems – particularly those using RAG pipelines or search embeddings – waste time scanning near-identical content instead of retrieving unique, relevant material.
Example:
If your CRM contains 20 variations of “Acme Inc.” as a customer record, every query for “Acme” produces a long list of redundant entries. An AI model generating a sales summary must filter dozens of identical opportunities, slowing its output and skewing analytics.
Impact: AI assistants spend more time parsing irrelevant data, which increases latency, cloud compute costs, and reduces the precision of results.
3. Inconsistent Insights and Analytics
Small variations between duplicate records can distort reporting and model training. One version might have updated revenue, another might list an old contact person, and another might carry incorrect industry tags.
Example:
Two Salesforce accounts for Blue Horizon LLC exist, one marked “Healthcare,” the other “Financial Services.” When training a churn or upsell model, the AI treats these as two unrelated entities. The resulting predictions become skewed, and segmentation accuracy falls.
Impact: Business insights are inconsistent across dashboards and reports, making it impossible to trust analytics-driven decisions.
4. Model Bias and Overfitting
AI models learn by identifying statistical patterns in data. When duplicate or near-duplicate examples dominate, models start to “memorize” them rather than generalize from diverse examples.
Example:
Suppose a support chatbot’s training data contains thousands of nearly identical case notes copied from the same product issue. The model will overemphasize that scenario and fail to perform well on other, less-represented cases.
Impact: The AI appears smart in testing but fails in production because it has overfit to duplicate-heavy data instead of learning general patterns.
5. Reduced Accuracy of Generative Answers
RAG-based or generative AI assistants depend on clean retrieval results to answer questions accurately. Duplicates increase the odds that the same piece of outdated or irrelevant content gets surfaced repeatedly.
Example:
An AI assistant in Salesforce Knowledge retrieves 15 articles that all contain the same outdated policy on warranty claims. Despite newer guidance being available, the model ranks the older duplicate higher because of keyword density – and returns the wrong answer to the customer.
Impact: Generative AI amplifies outdated or irrelevant content, lowering accuracy and creating customer service risks.
6. Higher Compute and Storage Costs
Every redundant record, attachment, or knowledge article consumes compute cycles for indexing, embedding, and querying. When scaled across millions of records, these inefficiencies translate directly to higher storage and infrastructure bills.
Example:
An organization with 5 million CRM records runs a nightly deduplication and embedding job for AI retrieval. If 15% are duplicates, that’s 750,000 of wasted embeddings, costing extra storage and compute time in vector databases or AI indexing systems.
Impact: Duplicate-heavy datasets inflate operational costs without improving results — an invisible tax on AI infrastructure.
7. Declining User Trust
AI is only as good as the data it represents. When users see repeated, contradictory, or irrelevant information, confidence in both the system and the underlying organization erodes quickly.
Example:
A Salesforce-powered chatbot gives three slightly different answers about a billing dispute. The customer assumes the system is unreliable and escalates to a live agent – increasing support costs and damaging the brand’s credibility.
Impact: Poor data hygiene turns what should be a time-saving AI feature into a frustration generator for customers and employees alike.
8. Governance and Maintenance Overhead
Duplicate content multiplies the effort required to manage data lifecycle and governance. Instead of updating one canonical record, admins must correct, merge, or retire several redundant ones.
Example:
A Salesforce admin updates pricing terms in the master KB article but forgets that 10 localized copies exist. Within weeks, users start referencing outdated versions, creating compliance issues and inconsistent customer communication.
Impact: Maintaining quality becomes a manual, error-prone process – and your governance policies lose effectiveness.
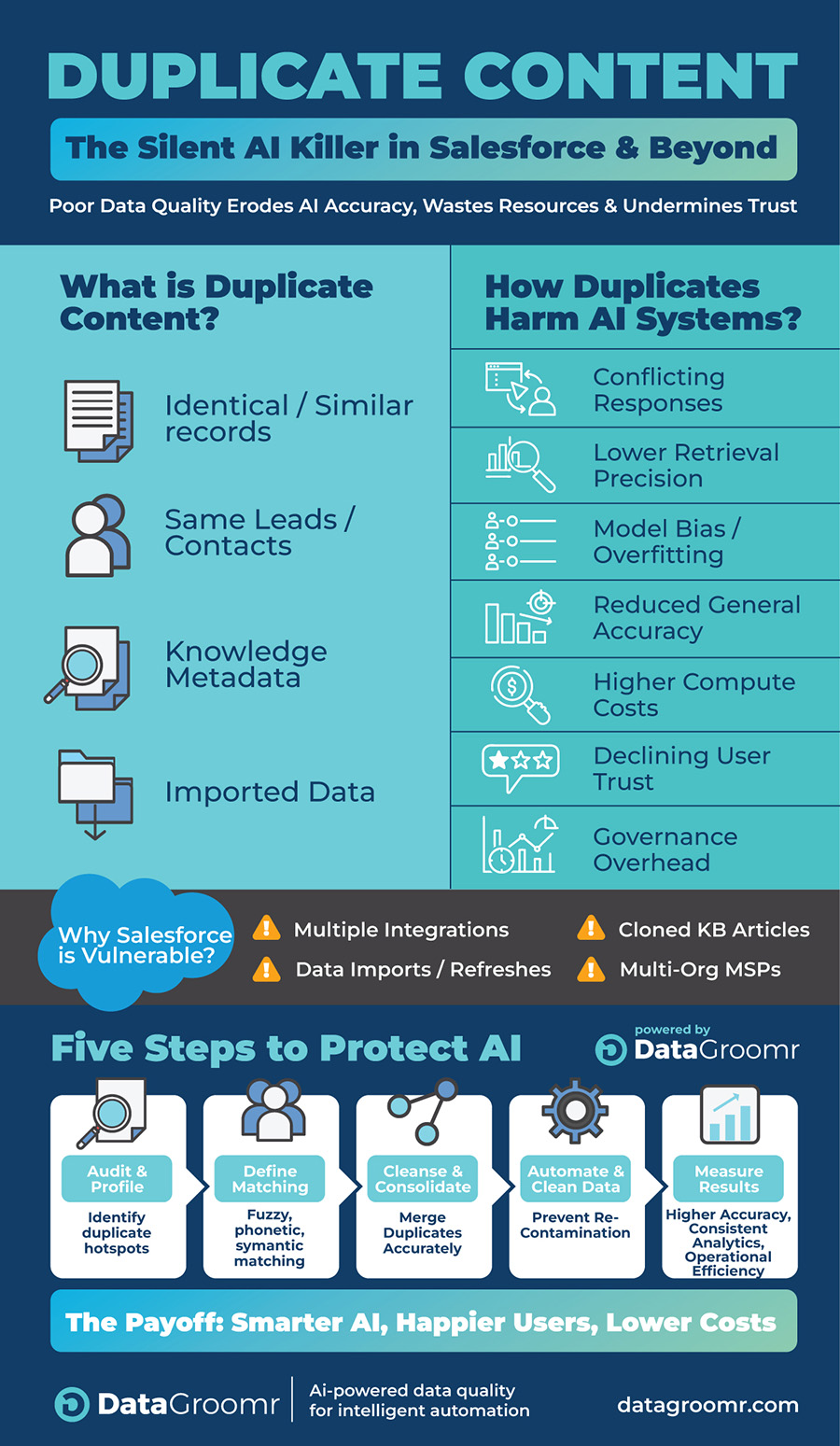
Why Salesforce Is Especially Vulnerable
Salesforce environments are particularly susceptible to duplication because of how data flows between systems:
- Multiple integrations from marketing, ERP, or partner systems create overlapping contacts or accounts.
- Knowledge articles are cloned across products, geographies, or service teams, introducing semantic duplicates.
- Data imports and sandbox refresh often reintroduce records that were previously merged or retired.
- Multi-org MSP environments multiply the duplication problem across tenants.
When duplicates persist, every AI function in Salesforce, from Einstein GPT to recommendation engines and predictive models, inherits the noise. The result: slower performance, conflicting answers, and skewed analytics.
Five Steps to Protect AI from Duplicate Content
Powered by DataGroomr’s AI-native data quality platform
1. Audit and Profile
Start by profiling your Salesforce and connected data sources. Identify which objects – contacts, accounts, opportunities, or cases – show the highest duplicate rates. Visualize their impact on AI use cases like lead scoring or chatbots.
2. Define Matching Logic
Move beyond exact field matching. Use fuzzy, phonetic, or semantic similarity, and account hierarchy logic to find true duplicates that differ by formatting or minor spelling. Account hierarchies should also be recognized through relationships (e.g., parent and subsidiary accounts). DataGroomr’s intelligent matching combines the precisions of the classic field matching with powerful machine learning models.
3. Cleanse and Consolidate
Merge redundant records and flag canonical sources. Retain the most accurate and complete version, consolidating related fields. DataGroomr’s AI-assisted merge engine ensures accuracy while preserving Salesforce relationships and ownership.
4. Automate Governance
Set up duplicate detection jobs that run automatically after data imports or API syncs. Use thresholds and notifications to alert data stewards. Periodically validate that deduplication rules remain effective as data patterns evolve.
5. Feed Only Clean Data into AI Pipelines
Ensure your deduplicated data is what gets indexed or embedded for AI models. Filter out outdated and redundant content before training or retrieval. This step is essential to prevent duplicates from repeatedly contaminating AI behavior.
The Payoff: Smarter AI, Happier Users, Lower Costs
Eliminating duplicate content yields measurable benefits:
- Higher accuracy: AI retrieves and learns from unique, up-to-date data.
- Lower compute costs: Reduced redundancy leads to faster processing and leaner infrastructure.
- Consistent analytics: Dashboards and insights align across departments.
- Improved user trust: Users get coherent, authoritative answers.
- Operational efficiency: Automated deduplication replaces manual cleanup.
For MSPs managing multiple Salesforce orgs, standardized deduplication creates consistency and value at scale, reducing risk across clients while improving performance metrics.
The Bottom Line
Duplicate content isn’t just a data hygiene issue; it’s an AI performance issue. As generative AI becomes core to CRM, service, and analytics workflows, duplicates silently erode accuracy, efficiency, and trust.
DataGroomr’s AI-powered deduplication engine ensures that Salesforce and connected systems stay clean, consistent, and ready for intelligent automation. Before you train your next model or deploy your next assistant – make sure your data is as smart as your AI.









