
Duplicate data causes a lot of frustration for business users. Compounding this problem is that the volume of data is increasing every day as companies launch sales and marketing initiatives to attract new subscribers and users. Despite automation, it still takes a lot of time and resources to identify duplicates. Current solutions require the development of complex de-duplication rules and data standardization to be implemented. However an alternative approach being explored by some companies is to utilize machine learning solutions. In this article, we would like to look at some interesting uses of machine learning to catch duplicates in other environments. Before we dive in, let’s take a look at how machine learning lends itself to data cleansing
How Does Machine Learning Identify Duplicates?
Machine learning algorithms are trained with data that contain the particular types of duplicates that need to be identified. The big benefit here is that since the duplicates come in all shapes and sizes, the system itself can learn to identify them. For example, it will take two existing entries it suspects of being duplicates and ask the user whether or not they are duplicates. If the user answers affirmatively, it will remember to mark such future entries as duplicates. So, how does this work in practice? Let’s look at some practical applications…
Identifying Duplicate Questions in Quora and Reddit
People from all over the world log into Quora and Reddit to ask questions and read responses from other users on a wide variety of topics. However, many questions are duplicates of each other and they need to be managed so that people do not post the same question over and over again. Since it is not possible to manually sift through all of the questions, these services use machine learning to identify duplicates. As an example, let’s use the questions below:
- How do I book cheap flight tickets?
- What are the best ways to get cheap flight tickets?
In order to train its machine learning algorithms to identify duplicates, Quora uses a massive dataset consisting of 404,290 question pairs and a test set of 2,345,795 question pairs. The reason that so many questions are needed is that so many factors need to be considered such as capitalization, abbreviations, and the ground truth. All of this is meant to find high-quality answers to questions, resulting in a better experience for all Quora users across the board.
Identifying Duplicates in Lines of Code
GitHub is a well-known platform, even for people who are not software developers. It is a place where developers can host, share, and discover software. According to GitHub’s website, they store petabytes of data that’s uploaded by users. What’s even more interesting is that the research shows that 93% of JavaScript on GitHub is duplicate. There are many different classifications of duplicates ranging from completely identical to those that are semantically similar but syntactically different. GitHub relies on machine learning to parse through all the code submitted by the users and identify the duplicates that either exactly the same or perform the same functions.
Decluttering Company Databases
At a time when the volume of data is growing exponentially and companies are looking to actualize large scale projects involving team members spread around the world, details may fall through the cracks. A good example of this is when a team shares, edits and stores documents. As time goes on this process is repeated over and over again, and document storage turns into a labyrinth of information. Some documents are outdated and no longer needed, but many others are duplicates of existing ones. Since it is not possible to sift through every document manually, there needs to be a technological solution.
One of the traditional tools that have been used is optical character recognition (OCR) but this has its limitations since it can only identify exact duplicates. Another option is the so-called fuzzy duplicate identification. For example, let’s say that one team member uploads a memorandum into the database. Someone else makes some minor revisions to it (i.e. punctuation changes, deletion of a repeated word, etc.). A solution powered by machine learning can identify these types of duplicates. The algorithm can be adjusted in terms of just how similar two documents need to be in order to be classified as duplicates. Such solutions allow companies to reduce the amount of data and required storage space and ensure smoother business operations.
Removing Duplicates in Advertising
Craigslist is a very popular platform that serves 700 cities in 70 countries and attracts users with its plain text-based layout that has remained relatively unchanged since the early 2000s. Sellers post all kinds of listings for products in hopes of reaching as wide of an audience as possible. When an item doesn’t sell, they often make changes to the phrasing of the ad and the system should not classify such changes as entirely new ads. For examples, let’s take a look at the ads below:
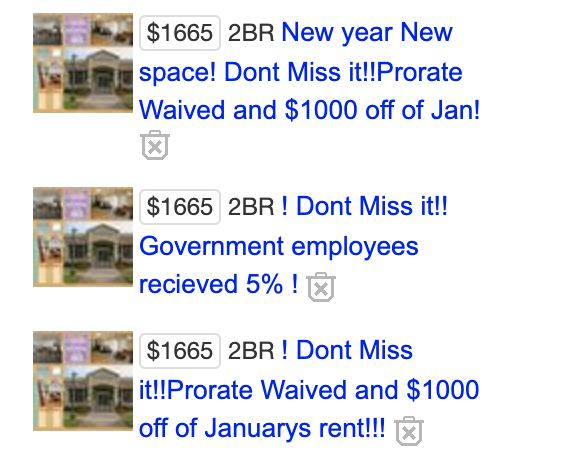
For a human reviewer, it will be fairly obvious that these are two versions of the same ad, but Craigslist’ algorithms need to be fine-tuned to detect the nuances. This is another example of a fuzzy duplicate. If left undetected it detracts from the user experience and results in a lot of confusion. When we consider the number of users, posts, languages, and other factors, machine learning becomes an indispensable tool. We also need to remember that Craigslist is only one example of such online platforms, but all use some variation of machine learning to deal with duplicates.
Identifying Duplicates in a Data Warehouse
Data contained inside data warehouses is used to make important business decisions and it is essential that the underlying information is accurate. However, in real life data obtained from external sources and stored inside the warehouse often contains many errors. As a result, companies spend a lot of time and resources on data cleansing which identifies and fixes all the errors including duplicates. An underlying problem that results in duplicates is that there may be many different representations of the same entity. A basic example of this could be something like a customer making multiple purchases from the same store. Even though it is the same person making the purchases, the system may classify as two different individuals.
When marketing and outreach campaigns rely on faulty data that contains duplicates there is a lot wasted time and money. For example, if customers receive multiple correspondence from the same source, they often classify that as spam. The result is that this customer becomes harder if not impossible to reach. Keep in mind, this is just for one customer. If there are hundreds or even thousands of duplicates, then the number of wasted resources could be astronomical. Such equivalence errors i.e. different representations of the value are hard to detect and you need to have sophisticated machine learning tools available to help you.
Duplicates in Your CRM
The final use of machine learning to catch duplicates that we will look at today is catching the ones in your CRM. Just like in the example above, sales, marketing, and customer service professionals will often use various values to represent the same person and you need to be careful that duplicate records are not created. A lot of the popular CRMs, like Salesforce, Zoho, Pipedrive and many others have some built-in rules to catch duplicates but very often they do not go far enough. Manually finding the dupes is time-consuming. For example, let’s say an employee stumbles upon a duplicate record. They report this to their Salesforce administrator who will manually need to clean the data and create a rule to catch duplicates that meet the same criteria in future.
Could you imagine doing this hundreds of times? If we think about the wide variety of duplicates that exist out there, this process can easily overwhelm your resources. You will constantly be finding duplicates that do not match the criteria in the rules. This is why machine learning is essential, as it learns to identify duplicates based on previous actions. For example, let’s say that the system presents you with two records shown side-by-side and asks you if they are duplicates. If you answer in the affirmative, it will learn from the example (and others) and update its algorithm allowing you to auto-merge these instances in the future.
Datagroomr Uses Machine Learning to Identify Duplicates
The best thing about DataGroomr is that it is powered by machine learning. There is no need to create complex matching rules and filters. The best part is that it constantly learns and improves. It also provides you with a side-by-side view of matched records allowing you to choose what data should be retained after a merge. The result is that you and your team have a consolidated view of your customer helping you to eliminate waste, close more deals and better support your existing customers.









