
When it comes to deduplication, most experts agree that machine learning is the most efficient approach to cleansing your Salesforce and other systems of duplicates. However, while the machine learning approach may be the smarter way to go, it’s not exactly clear why. The science behind the machine learning algorithms that power DataGroomr increases the health of your data. In this article, we will help you understand exactly what that science is accomplishing. To start, machines are taking a lesson from how humans think…
Telling Machines to Think Like Humans
Let’s take a look at the following records:
| First Name | Last Name | Phone Number | |
| Shaquille | O’Neal | (555) 743 8901 | shaq34@tbs.com |
| Shaquil | Oniel | 743-8901 | shaq34@tbs.biz |
If we look at these records empirically, it’s pretty obvious that these records are duplicates, and they are referring to the same person. However, could you explain exactly why? You may start by listing all of the similarities between the First Name and the Last Name. The email address and phone numbers are also similar. However, how would you teach a machine to recognize all of these things and, in general, think like a human?

One of the ways data scientists accomplish this is through the use of string metrics. While this may sound like a complex term, it basically indicates various measurements that describe the distance between two or more strings of texts. When we delve deeper down into string metrics, we see that there are many different types. For example, there is the Hamming Distance, which counts the number of substitutions that must be made to turn one string into another. If we return to the table above, we see that there are two versions of the First Name and only two substitutions are necessary to turn “Shaquil” into “Shaquille” so the Hamming Distance would be 2.
There are many other types of string metrics, and all of them are used by data scientists to train machine learning algorithms. Some of the most popular ones include:
- Hamming Distance – This method counts the number of substitutions that are required to turn one string into another.
- Levenshtein Distance – This string metric expands on the Hamming Distance by allowing operations such as deletion and insertion in addition to substitution
- Jaro-Winkler Distance – a string metric measuring an edit distance between two sequences
- Learnable Distance – This one takes into consideration that different edit operations have varying significance in different domains.
- Sørensen–Dice coefficient – This one measures how similar two strings are in terms of the number of common bigrams (a bigram is a pair of adjacent letters in the string).
One of the major benefits of the machine learning approach is that unlike a rule-based deduplication tool you are not required to set up the matching rules and constantly keep adding new ones to account for all of the “fuzzy” duplicates. The machine learning algorithms automatically select all of the string metrics to compare records based on the examples that you “feed” to the system, this approach is called Active Learning. It gives you the best of both worlds: they analyze records just like a human and they have much greater computational power.
Active Learning
In the previous section, we talked about how machines are able to analyze data like a human, but just like with human intelligence, machine learning systems are always learning new things and improving their existing knowledge. The way this all works on a practical level is that when you label two records as duplicates (or not), the system will “learn” from these actions and will adjust its algorithms accordingly to identify such records as duplicates or unique in the future. It will set the field weights for each individual field and use those weights when comparing future records.
This is very important because in many rule-based deduplication tools, you need to set these field weights yourself. However, how are you supposed to know, for example, if the Email field is two times more important than the Last Name field or 1.7? There’s no way a human would be able to compute something like this. In fact, not only will the machine learning system calculate the field weights, but it will apply them to future records. This saves you a lot of hassle because otherwise, you would need to create a new matching rule and adjust the field weights every time a new duplicate is discovered.
Choosing Smart Comparisons
When we look at the rule-based approach to deduplication, we see that the system would need to compare every new record against existing ones. Not only is this inefficient, but it’s also very time-consuming. After all, even if you have a modest number of records, let’s say 100,000, and you want to upload 50,000 more, the traditional rule-based deduplication apps would need to compare each new record with existing ones meaning that there would need to be 5,000,000,000 comparisons done (100,000 x 50,000).
The machine learning-based approach is much smarter because it uses the string metrics, we talked about earlier to block together similar-looking records. This can be something like the first three letters of the First Name field, records that have the same zip code, and many other parameters. This greatly reduces the number of comparisons that need to be made. The following diagram depicts how the blocking method works:
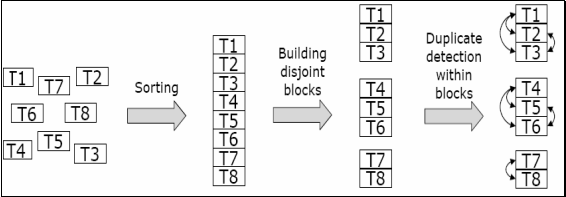
Another major benefit of such an approach is scalability. Let’s say that we have only 50,000 records this time, and we want to add 5,000 more which means that 250,000,000 comparisons would need to be made if we were to use the standard approach. Even if your system is able to compare 10,000 records per second, it would still take almost seven hours to make the full comparison and identify duplicates. The machine learning approach allows you to minimize the number of comparisons that need to be made, thereby speeding up the deduplication process.
Leverage the Power of Machine Learning-based Deduplication
As we’ve seen from all of the information presented above, the machine learning approach is a lot smarter than rule-based deduplication. If you want to take advantage of machine learning-based deduplication, consider trusting DataGroomr with all of your data cleansing needs. We are the only machine learning-based deduping app on the AppExchange, and we can help you avoid some of the hassles that are inherent in rule-based deduping tools.
Try DataGroomr for yourself today with our free 14-day trial.









