
Our first release of 2023 brings several user convenience features and a highly requested enhancement for merge rules.
Read on to discover the highlights and, as always, you can find a detailed list of all our updates and fixes on the DataGroomr Support Portal.
Keep in mind that many of the updates we make were driven by requests submitted to the Ideas Exchange portal. So, keep them coming.
Use Values from Related Object with Merge Rules
In this release, we introduced several enhancements for Supervisr module, but the most requested one is to leverage data from related objects when building merge rules. To accomplish this previously, users had to create formula fields in target object, which was cumbersome.
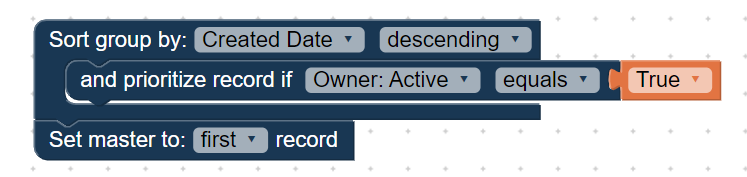
Moving forward, users can simply select any related object, followed by the field (from the Available Fields in the Rules Editor), and use it with either the Master Record or Field Value Rule.
For example, the following rule sets master record from a group of records to be the oldest record with an active owner.
Auto-run Analysis Prior to Running a Job in Schedulr
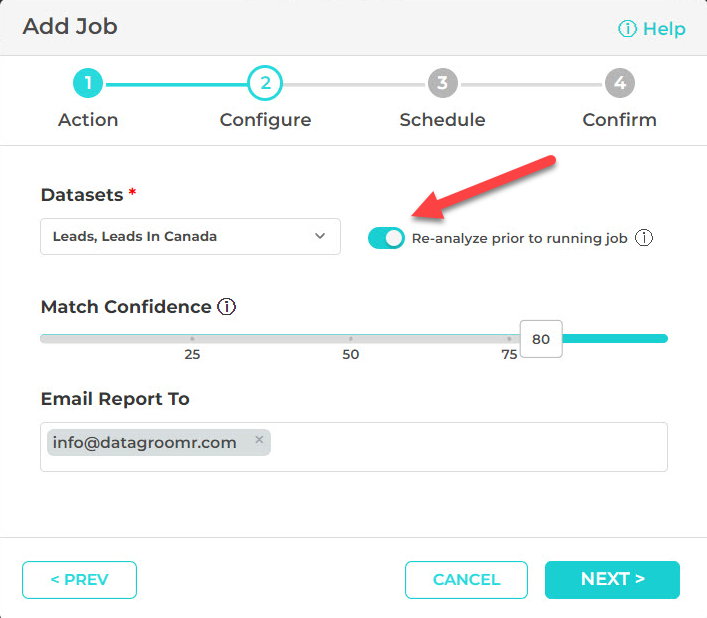
Schedulr Job module is a great way to automate tasks such as Mass Merge and Convert. Jobs like these rely on up-to-date information on which records are duplicates and which are not. However, in some cases, this analysis had been done days in advance, preventing the merge from including all the current duplicates.
This release includes a new switch in the job configuration wizard to kicking off the analysis prior to executing the rest of the job. If the switch is enabled, all of the selected datasets will be reanalyzed.
Display Unmapped Fields of Matched Records in Importr
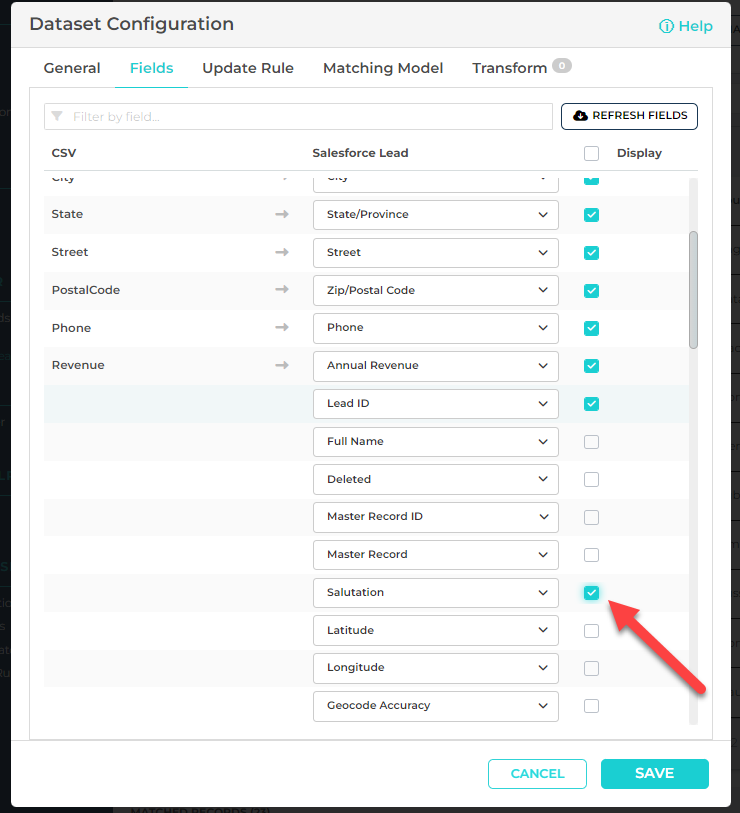
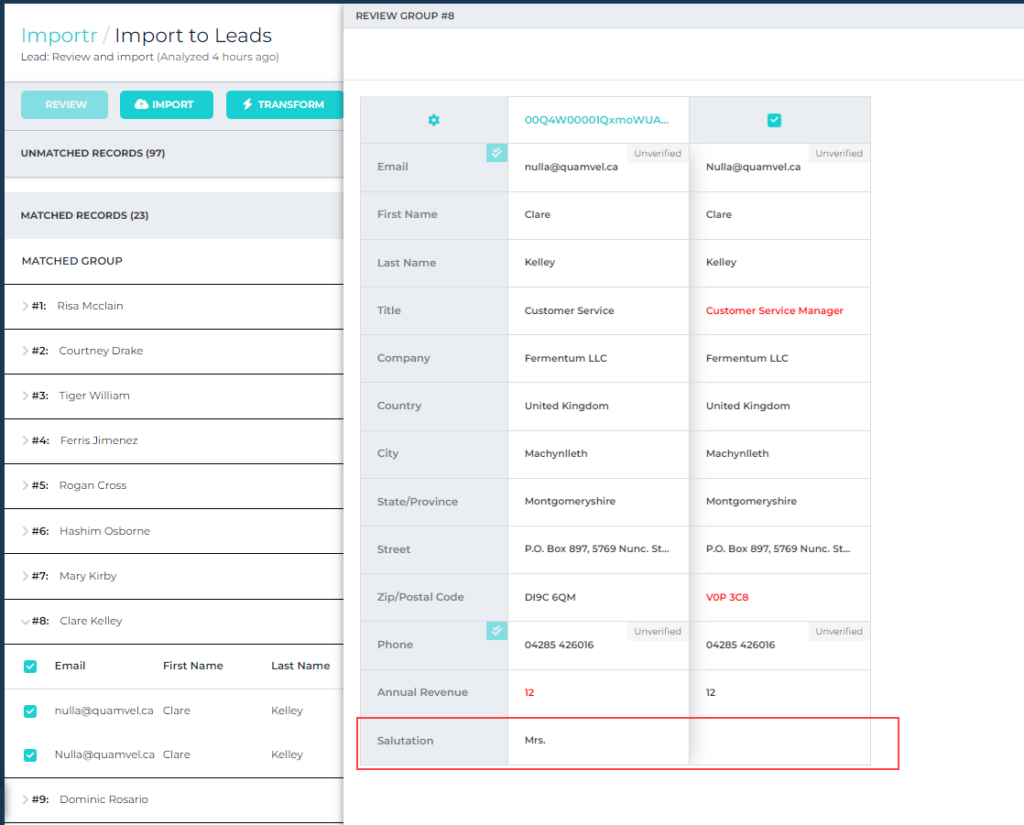
Importr module compares data in CSV files with Salesforce, to identify and prevent duplicates prior to importing. When comparing duplicates in Importr, users had been limited to seeing only the fields that are contained in the CSV file.
In this release, we added the functionality for users to select other fields in Salesforce and display them when comparing CSV data to Salesforce. To do this, users can edit any Importr dataset and add the fields from the provided list.
Change Order of Fields for Matching Model
When creating new matching models (Machine Learning or Classic), the order of the fields could not be modified. Previously, they were simply displayed in the order added. Users asked to be able to change this order for convenience when training models and that is available with the current release.
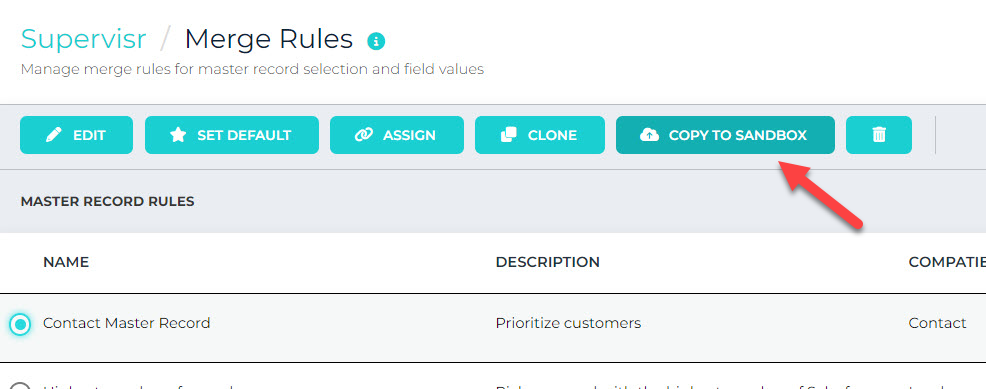
Copy Rules and Models between Prod and Sandbox Orgs
In the previous release, users were given the ability to move rules and models from Sandbox to Production. In this release, we extend the capability to go the other way. A good use case for this is when customers refresh their Sandbox – Salesforce actually creates a new org. Consequently, the Rules and Models are lost. This feature gives users the capability to move them back from Production.
What’s Coming in the Next Release?
There are two major features that we are working on. As mentioned in the last release notes, we will be releasing a brand-new Lightning Component for Salesforce, focusing on email, phone and address verification.
Prior to that, we are working on adding tagging functionality to Trimmr and other modules. Users will be able to Tag matched groups and records and perform activities based on these tags.
Please follow these release announcements to stay tuned and as always, we appreciate your feedback.
If there are other features that are important to you, we invite you to submit them to the Ideas Exchange portal or vote on existing features already there.
As always, we would like to remind you that we offer a free, 14-day trial of DataGroomr. Please feel free to forward this article to your Trailblazer colleagues. They can start the Free Trial by logging in with their Salesforce credentials. There is no setup required and, as you know, you can get a handle on the duplicate management of your data right away!
Happy DataGrooming, Trailblazers!









